
What are the historical and existing efforts to employ digital technologies for exploring or generating prosody? It turns out, digital technologies seem to have contributed more to the analysis of prosody than to the composition of metrical verse in English.[1] Poet and early computer-based prosody pioneer Charles Hartman notes a similar sentiment in his autobiographical Virtual Muse (1996):
A search of the catalog in a big library turns up quite a few cross-references between “computers” and “poetry.” But virtually all of the books and articles referred to have to do with “computer stylistics.” That is, they’re documents in the field of literary criticism, and they represent endeavours to study poetry by means of computers, not experiments in making poetry with computers. [...] Stylistics is not my field. But one of my fields has been prosody: the study of poetic meter and rhythms. So one of the first large computer projects I undertook was a Scansion Machine.[2]
To be fair, my field is also not strictly in stylistics or in prosody, but in information science and textual scholarship. As a part of my dissertation research, I am working with literary scholars and archivists to facilitate critical dialogues on literary artifacts including audio and audiovisual recordings of poetry readings; one project includes a digital platform for Robert Frost. Prosody is a part of the conversations I am hoping to accommodate, and that is why I am curious to learn how digital technologies might have informed the epistemologies of prosody to date. By taking Hartman’s Scansion Machine as a point of departure, I would like to share my working survey of digital prosody projects and prosody-related visualization methodologies below. [3]
Scansion Machine (1981)[4]
Written by Charles Hartman, Scansion Machine was designed to scan a line of iambic pentameter. According to Hartman’s autobiographical records, the program was taught to follow these five scansion steps based on his own pedagogical experience: 1) find multisyllabic words and mark where the stresses would fall; 2) place stresses on the important, monosyllabic words; 3) mark the rest as slack; 4) divide preliminary marked syllables into feet; and 5) write out the finished scansion.[5]
In the description of the Scansion Machine, we can see how Hartman tackled the irregularity of scansion in a groundbreaking manner. For instance, in order to indicate where the metrical pattern influences the rhythm of a line, Scansion Machine was programmed to use a % mark to indicate a “promoted stress.” For identifying a situation that would call for either a headless line or one or more metrical substitutions, the Scansion Machine was designed to first ignore the potential headless reading and proceed; if the line continued with more than three consecutive trochees, the Scansion Machine was then programmed to read it as a headless line.[6] Attesting to Hartman’s innovative attempts to identify a comprehensive rule that governs the complex metrical patterns, the Scansion Machine set a rigorous precedent for the automation of scansion.
Though there remains no executable file for me to demonstrate how the Scansion Machine operates today, suffice it to say that the program was a part of Hartman’s productive, exploratory research that would later bear fruit. According to his autobiographical notes, Hartman also envisioned combining the Scansion Machine and other lineation and random-text generators he had created in order to create a word processor with a meter checker. Hartman, however, set aside further sophistications of the Scansion Machine for the next twenty-odd years, stating, “I’m a poet, not a software entrepreneur. (And no entrepreneur would bet his shirt on a word processor for poets).”[7]
Poetry Processor (1986)
Thinking analogically about the current climate of entrepreneurial industry in 2017, Hartman’s decision to not pursue inventing a meter checker is not surprising. But there were those who thought otherwise—Michael Newman, Hillel Chiel, and Paul Holzer, the developers of proprietary software Poetry Processor.[8]
In the article jointly published in the computer magazine Byte, Newman et al. described how Poetry Processor was designed to interactively assist users in composing metrical verse. [9] First, users would choose a metrical form provided by Poetry Processor and try their hand at it. The processor, in response, would then impose the metrical beats regardless of the rhythm of the line, in order to prompt users to negotiate the metrical structure and the rhythm of a language. Take, for example, how Holzer, one of the developers, explained the process:
So, were Shakespeare trying to compose trochaic pentameter, with the metric pattern -. / -. / -. / -. / -. /, the processor would reply with “SHALL i COMpare THEE to A sumMERS’S day.” He would read this to himself, trying to put the stress on the uppercase syllables. Noting the rhythmic clumsiness, he might rewrite his line as follows: “To a summer’s day I shall compare thee” and the processor would respond: “TO a SUMmer’s DAY i SHALL comPARE thee.” Sounds better! [10]
It is questionable whether Holzer successfully demonstrated Poetry Processor’s usefulness, let alone its functionality, with the imaginative Shakespeare’s revision process. Nevertheless, it is apparent that the priority of Poetry Processor was to prompt users to comply with the metrical form, and that kind of regulation would be useful for a poet like Robert Frost who might think writing free verse was like playing “tennis with the net down.”[11]
Above all, Poetry Processor was a novel enterprise and it attracted some press coverage. The New York Times reporter Peter Lewis, for example, introduced Poetry Processor repeatedly, and with amusement. In the first article—published in September 1988 and dedicated solely to the introduction of Poetry Processor—Lewis opened the article with a whimsical note: “SHALL I compare thee to a perfect word processor? Hmmm. Michael Newman’s Poetry Processor [sic] informs me that my first effort at writing a software review in iambic pentameter has gone awry. Fie!”[12] The English Journal—published by the National Council of Teachers of English (NCTE)—also published Poetry Processor’s commending advertisement:
THE POETRY PROCESSOR provides students with a 20,000-word on-line rhyming dictionary, a form editor that supplies dozens of color-coded forms, or enables students to create their own, a scanner that actually counts syllables and assigns stress, and examples of all these forms in poems geared for three age levels. Tested at Yale, Stanford, University of Washington, community colleges, high schools, and on children as young as 9, the software consistently culls competent, finished sonnets. [original emphases][13]
According to Lewis’s report, Poetry Processor was priced at $89.95 (equivalent to $199.30 in 2017) and was marketed together with two other programs called Electronic Rhyming Dictionary and Orpheus A-B-C, complementing the Processor with rhyme-scheme suggestions and metrical-form tutorials respectively.[14]
These records of advertisement sound appealing, but whether Newman et al. found Poetry Processor worth betting their shirt calls for further research.
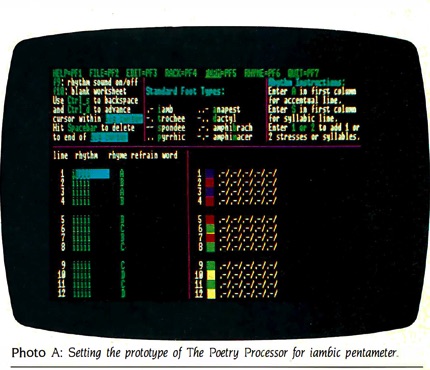
[An Image of Poetry Processor Published in Byte Magazine, February 1986]
Praat (1992—Present)
Unlike the other programs discussed in this Colloquy essay thus far, Praat is not a tool designed originally for application to verse. Instead, it is speech-analysis software that has been adapted by prosodists since the early 1990s to help address the limitations of scansion for apprehending the full prosody of a poem. Developed by Paul Boersma and David Weenink, Praat enables users to analyze, synthesize, and manipulate digital speech recordings.[15]
Given that Praat is designed for speech analysis, it is suitable for the analysis of acoustic correlates such as pitch and formant (phonetic quality of a vowel), as well as the examination of sound’s physiological elements such as nasality and breathiness. Praat also enables juxtaposed analysis of multiple audio recordings; the comparative intonation analysis of performance variants might be of interest to prosodists. Additionally, Praat lets users experiment with vowel duration by manipulating its parameters—something that is, as we will see later, similar to what the participants of Poem Viewer also seek to address.[16]
Since Praat remains available on the Internet—thanks to constant updates by Boersma and Weenink—let me present a short, introductory demonstration. In the following video, I compare two readings of “Mending Wall” by Robert Frost to show one of the many types of analysis Praat accommodates. One recording is from the 1997 CD-ROM edition of Frost edited by Donald G. Sheehy, Robert Frost: Poems, Life, Legacy.[17] The other recording is from the HarperAudio, an online broadcasting platform. In comparing these recordings, I am interested in identifying whether these two recordings are identical; and if so, whence their original recording is and whether migration of the recording to different media and platforms has altered its sonic features.[18] My inquiry, of course, does not strictly concern prosody. However, I hope it sheds light on the materiality of digitized audio recordings, should prosodists wish to have Praat process audio recordings available on the Internet.[19]
[A Comparative Analysis of Frost’s “Mending Wall” via HarperAudio & the 1997 CD-ROM edition]
the Scandroid (2005—Present)
Following his original idea implemented in the Scansion Machine, the Scandroid is Hartman’s further developed program, designed to scan English verse in iambic and anapestic meters. Just as Praat can be downloaded and run on the users’ desktop, we can still test the Scandroid today. Additionally, the Scandroid’s source code and the users’ manual are available online, detailing the program’s scansion rationale and mechanism. Hartman’s choice to publish the source code—a common practice in the fields of software engineering and computer science—indicates that Hartman invites users to interpret and discuss the program’s fundamental mechanism. With this decision, Hartman seems to have been ahead of the intellectual curve, as it was only in 2006 that the need for examining the source code in the humanities resulted in the establishment of the field of critical code studies.[20]
Picking up on Hartman’s invitation, let me offer a glimpse of what critical code studies might entail by rephrasing how Hartman describes the Scandroid’s scansion algorithm in the users’ manual. Read the following steps as if Hartman is teaching the Scandroid how to scan a metrical line, and note how these steps are more meticulously constructed compared to those of the Scansion Machine: [21]
1) identify syllables and lexical stresses of a line;
2) assign and count preliminary foot marks (either slack or stress)
3) determine which of the two types of feet assignment is more fitting by answering the following questions in sequence:
- Does the end of the line disrupt the iambic pattern and might it alter the line’s length in syllables? (e.g., Does the line end with an amphibrachic feminine ending, second paeon, an anapest yielding a third paeon, or a spondee yielding a palimbacchius?) OR Does the line start as headless?
- If not, proceed to try the foot type “3.b” below.
- If yes, mark off the number of feet that need special treatment. Count the rest of the feet in the line, and multiply by two. (e.g., There is one amphibrachic foot at the end of a presumably iambic pentameter line. Extracting one special foot from the regular iambic pentameter foot count gives four. Multiply four by two, assuming each foot has two syllables.)
- Does the computed number of syllables match the actual number of syllables among the presumably iambic feet?
- If not, and there are more syllables in reality, search for one or more anapests substituting for the iamb.
- If not, and there are fewer syllables in reality, search for an isolated stress with no preceding unstressed syllable (e.g., after a caesura).
- Locate the longest sequence of iambs in the line.
- Divide the remainder into simple, plausible feet.[22]
The Scandroid’s interface lets users follow these steps, and, if needed, make interventions to override the programed stress patterns and the meter-scheme assignment. In this manner, the Scandroid indicates there is a room for debates surrounding scansion and offers a self-reflective opportunity for users to examine the implication of divergence between meter and rhythm. For an example, please see the video below, in which I try to navigate the scansion process of Robert Frost’s “Mending Wall.”[23]
[Scanning Parts of Frost’s “Mending Wall” (1995 Library of America Edition) with the Scandroid]
Lastly, let me revisit another way prosodists and other users might wish to leverage an open-software project like the Scandroid. The aforementioned algorithm is based on Hartman’s description in “the Scandroid Manual” written in “human” English language. If users are so inclined, the corresponding code written in a high-level programming language called Python can be found in the source file titled “scanfuncs.py” for cross-examination.[24] Reading the source code calls for a basic proficiency in Python, but users who are not familiar with a programming language may nevertheless wish to consult Hartman’s marginal comments in the source file, as they offer a glimpse into the behind-the-scene labor that went into the software development.
for better for verse (2008—Present)
Developed by Herbert Tucker, for better for verse (4B4V) is a pedagogical, web-based project that facilitates scansion drills. According to Tucker’s “Memoir,” 4B4V is designed to offer immediate feedback for undergraduate scansion exercise assignments.[25] In the same “Memoir,” Tucker also humorously suggests that Harman’s the Scandroid should be rated PG-19 owing to its highly specialized treatment of scansion, indicating that 4B4V—designed especially for students who are exposed to the art of scansion for the first time—complements the Scandroid.
Unlike the Scandroid, 4B4V comes with pre-installed poems, which are in the public domain, leveraging, to Tucker’s benefit, the tradition of English metrical verse published before 1923.[26] Those poems are also pre-encoded in XML according to the TEI guideline (a standard markup and preservative practice in the humanities) and, for the purpose of drills, with the “correct” stress, feet, and meter marked. These markups operate as the feedback system, checking whether users scan the line correctly or incorrectly as indicated by green and red lights, respectively.
Concerning the design choices of 4B4V, Tucker acknowledges his “right-hand prejudice” for iambic and anapestic meters over trochaic and dactylic meters, as well as his firm argument for how a certain poem ought to be scanned. He writes, “in 4B4V I firmly insist that Shelley’s ‘Life of Life’ lyric from Prometheus Unbound is written in trochaic tetrameter: when the poem’s dropdown meter box is invoked, that and only that answer gets the green light for correct.”[27] At the same time, Tucker does offer an occasional yellow light signal for the inherently ambiguous scansion, provided that the poems available in 4B4V are “coded consistently so as to give the novice a firm footing.”[28]
If users feel compelled to consult how each poem is encoded, they can click right in a web browser of their choice and choose the option “view page source.” In a separate window, users can analyze the underlying XML encoding of 4B4V. In the following video, I demonstrate how 4B4V operates and examine its underlying mechanism. While I wish I could demonstrate how 4B4V lets me cross-examine Frost’s “Mending Wall”—so as to illustrate how each program introduced in this Colloquy essay processes the same poem differently—I am confined by the affordances of 4B4V and must choose from the three Frost poems the platform offers. As such, I will try my scansion hand at “The Wood-Pile” (1914). I then juxtapose my 4B4V interaction with my listening to the audio recordings of Robert Frost’s performance from the 1997 CD-ROM edition, not to indicate what may be the “correct” scansion but rather to mull over how the rigid framework of 4B4V might be telling when thinking about the performance of a poet like Frost. [29]
[Testing the 4B4V Scansion Drill with Robert Frost’s “The Wood-Pile” (1914)]
Myopia (2011—Present)
Myopia is a desktop software program developed by an interdisciplinary research team—composed of Helen Armstrong, Laura Mandell, Gerald Gannod, Eric Hodgson, and Manish Chaturvedi—in order to assist a close reading of poetry.[30] Originally built as a part of Chaturvedi’s master’s thesis for a degree in computer science, Myopia is designed to render the pre-encoded works hosted in The Poetess Archive. As Mandell described during the 2012 Alliance of Digital Humanities Organizations (ADHO) conference, Myopia adapts 4B4V’s standard TEI pre-encoding method and is designed as a pedagogical tool, to demonstrate the close reading not only for meter but also for additional literary components of poetry.[31]
What is unique about Myopia is its graphic notation system, which indicates different metrical elements in an abstract manner. Pre-encoded elements such as syllable counts, stressed syllables, syllabic durations (either “long” or “short”), feet, and meters can be represented through different colors and shapes (e.g., green for pyrrhic; a larger box size for long syllables).[32] These critical design decisions mainly concern how to assist a close reading practice by rendering rich, pre-encoded “information” without overwhelming users, as well as how to offer a heuristic strategy to study the poetic structure of a work by way of abstraction.[33] As such, users can choose how many metrical elements and literary tropes should be rendered via the Myopia interface. By hovering the cursor over each graphic element, they can also learn conceptual terminologies corresponding to the color and size keys.[34] Additionally, Myopia accommodates a juxtaposition of texts, anticipating, and staging, a comparative analysis of different works or an examination of the same work encoded by different users, all via its prosody visualizations, facilitating an easy collation.[35] Such flexibility, in my opinion, complements the rightly rigid structure of a program like 4B4V by shedding light on the implication of varieties among metrical encodings.
Lastly, Myopia offers the option to listen to some of the audio recordings of the works in The Poetess Archive. While those audio files are not transcribed or encoded in XML according to the TEI guideline, combining audio resources with text analysis is interesting, to say the least, and further complicates the multidimensionality of prosody analysis, as we will see in later projects such as Drift.[36]
Currently, Myopia exists in the form of source code, and upon my request, Mandell kindly shared the code with me. Having spent weeks trying to compile and run those files by reconstructing Myopia’s native development environment, however, I needed to abandon my reassembling effort owing to the versioning discrepancy among co-dependent software—an unfortunately common issue digital archivists and conservationists are currently addressing and trying to mitigate. Therefore, instead of a video demonstration, let me share a screenshot image offered in Chaturvedi’s thesis, so as to offer a glimpse of the Myopia interface.
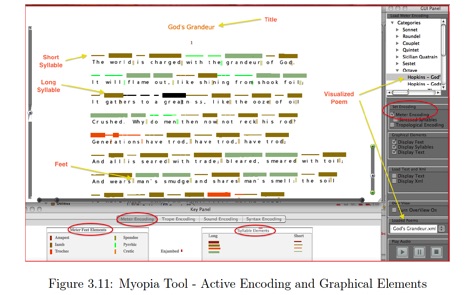
[A Screenshot Image of the Myopia Interface from Chaturvedi’s Thesis]
Poem Viewer (2012—Present)
Built by a group of researchers led by Katharine Coles and Min Chen, Poem Viewer is another project that is designed for users to examine the sonic structure of poetry through visualization.[37] Based on the phonetic transcription of poetry, Poem Viewer is programmed to render as many as twenty-six poetic attributes including sonic features such as phonetic type (vowel or consonant), vowel length (long, half-long, extra-short), stress, and recurrence of phonetic sound (rhyme, assonance, and alliteration).[38] In order to observe how the sound would “develop” across the text (e.g., “the repetition of the long ‘o’ sound linking ‘cold’ and ‘remote’ evolving into the repeated long ‘u’ sound of ‘blue’ and ‘estuaries’ in Louise Bogan’s free verse “Night”), the research team employed a glyph system to indicate such physiological features as vowel positions (e.g., close-front, mid-central, open-back) as well as consonant features (e.g., voiceless top-front, voiceless top-back, voiced middle-back).[39]
While Poem Viewer has little to do with the visualization of meter and rhythm, the program is first of its kind to offer a glance at the careful phonetic patterning of poetry including that of free verse. In the following video, I demonstrate how the phonetic transcription of Frost’s “The Wood-Pile” may be processed by the current iteration of Poem Viewer.[40]
[Processing the Phonetic Transcription of “The Wood-Pile” via Poem Viewer]
ARLO (2012—Present)
In addition to Praat, ARLO is another program that can potentially enable prosodists to analyze audio recordings of poetry. ARLO stands for Adaptive Recognition with Layered Optimization, and it was originally developed for ornithology. ARLO, since 2012, has been reinvented for humanities scholarship under the leadership of Tanya Clement. Just like Praat, ARLO is, according to its “Documentation for Humanists,” capable of extracting prosodic features such as pitch, rhythm, and timbre from a large-scale audio repository such as PennSound. The sharable, working version of code is not yet available, but the research group hopes to have it published soon.[41]
Among the complex features ARLO offers, I am most excited about its possibility for searches based on sonic features rather than the standard lexicon-based search. According to Clement et al., ARLO’s machine-learning algorithm can memorize the sonic patterning of an audio file and seek matching examples from a collection of audio resources. [42] Such a system would not only complement the logo-centric search system but may also shed light on aspects of sound recordings that we have not yet articulated but that are still worth investigating.
With a poet like Robert Frost who was celebrated, at the onset of publishing his 1915 first American edition of North of Boston, for composing both the landscape and the soundscape of New England, [43] I would like to examine his work in conjunction with a collection such as the American Folk Life Center’s audio collection at the Library of Congress. To the best of my knowledge, save for the 1933 recordings of “Code,” most of Frost’s reading sounds carefully calculated, if not monotonous, as if to emphasize his art of versification, negotiating the irregularity of vernacular accent and the formality of meters.[44] As Frost himself acknowledges in his 1913 letter to his student and friend John Bartlett, some of his contemporary critics, too, note Frost’s craft in their reviews. According to a 1914 review by Harold Monro:
Mr. Frost appears to have studied the subtle cadences of colloquial speech with some peculiar and unusual apprehension. The jerky irregularity of his verse is due to the fact that the laws of emotional value have evidently overmastered the rules of prosody. […] The rhythm of his verse escapes the usual monotonies of stress; its current follows the stresses of what it relates; it is like an indicator passing along some continuous fluctuating line, or it has the sound of a swift and excited voice.[45]
But how distinctively “New England” was Frost’s poetry? Would the machine match Frost’s reading to other ethnographical audio recordings sampled in the early-twentieth-century New England? Or is it our cultural construct that makes us want to read Frost as a “poet star of exceptional magnitude” who has “risen for New England”?[46] ARLO might enable such an inquiry once it becomes publicly available.
To reiterate, unique contributions of ARLO to prosodists may be its close working relationship with ethnographic and music collections, in addition to literary audio collections, offering, consequently, multiple angles to explore prosody.[47] In the meanwhile, various research conducted with ARLO can be found on its project page High Performance Sound Technologies for Access and Scholarship (HiPSTAS). Additionally, demonstration videos put together by Clement may offer a glimpse into how ARLO operates.
Poemage (2014—Present)
One thing I noticed as I had conducted this digital prosody project survey is that, just like any other academic disciplines, there is a social network of people who are working on the digital exploration of prosody and that every project is often (but not always) in conversation with other projects. As for Poemage, Katharine Coles—one of the co-principal investigators of Poem Viewer—leads a team of the University of Utah scholars composed of Nina McCurdy, Julie Gonnering Lein, and Miriah Meyer.
According to its research team, Poemage is desktop visualization software for “exploring the sonic topology of a poem,” i.e., “the complex structures formed via the interaction of sonic patterns across the space of the poem.” Notably, Poemage’s backbone is another open-source project called RhymeDesign, developed by McCurdy, Meyer, and Vivek Srikumar. Just as Poem Viewer ventures into the sonic structure of free verse, the RhymeDesign research team at the School of Computing deploys four types of expansive classification of rhyme—sonic rhyme, phonetic rhyme, visual rhyme, and structural rhyme—in order to assist poets in examining rhyme, broadly construed. [48] In order to achieve this goal, McCurdy et al. adapts a linguistics approach and processes words in a more granular manner than, say, that of Hartman’s the Scandroid, by parsing syllable units into phonemes. [49]
With phonemic units, RhymeDesign can identify twenty-six types of rhyme types—such as identical rhyme, perfect feminine, and perfect dactylic—when users submit a poem.[50] Poemage, built on top of RhymeDesign, visualizes, in a calculated manner, how one or more rhyme types establish relationships as the poem progresses, including a graphic rendition of the poem’s complexity McCurdy et al. rightly coined as a “beautiful mess.”[51]
In the following video, I demonstrate how to upload a poem of your choice to Poemage, as well as how Poemage would process Frost’s “The Wood-Pile” text. Note how Poemage’s visualization differs from that of the aforementioned Poem Viewer, reflecting a further developed approach to demonstrate how particular vowel and consonant sounds develop in a poem.
[Seeing Phonemic Relations within Frost’s “The Wood-Pile” via Poemage][52]
Drift (2016—Present)
Thus far, I have introduced projects that process prosody in two distinct ways. One is via textual analysis (Scansion Machine, Poetry Processor, the Scandroid, for better for verse, Myopia, Poem Viewer, and Poemage), and the other is via audio signal processing (Praat and ARLO). Drift is one of the most recent efforts of the latter, developed by a team of scholars led by Marit MacArthur.[53] In her Jacket2 article introducing Drift, MacArthur writes how open-source software such as Praat has been a common option for speech analysis, but how the robustness of such software often comes with a steep learning curve, and its interface—reminiscent of the 1990s—does not necessarily help in terms of user-friendliness today. That is why MacArthur et al. offers Drift, a more accessible option for literary scholars who are concerned with pitch, intonation, rhythm, stress, and other paralinguistic features of performed poems.[54] Additionally, MacArthur—who has used ARLO and Praat—seeks to make Drift produce less erroneous pitch values than the existing programs especially concerning the processing of “noisy” recordings (owing to the background noise, the material condition of a medium, or non-voiced speech sounds such as fricatives or plosives).[55]
Developed by Robert Ochshorn and Max Hawkins, Drift lets users upload a digital audio file and renders a waveform graph and a pitch contour. Drift also incorporates another project of Ochshorn and Hawkins, Gentle, which enables the forced alignment of a transcription of the audio file, enabling users to analyze the pitch contour and the transcription simultaneously.[56] While Drift does not allow users to listen to the audio file concurrently, it does offer a downloadable dataset in a .csv file. By downloading a .csv file, users can consult the pitch of the audio source by 0.01 seconds—something, MacArthur suggests, that can be useful for computing mean and median pitch and, possibly, intonation patterns.
MacArthur offers both the online demo version and the source code via the GitHub repository, and recommends the use of the latter for a large-scale pitch analysis.[57] Installing Drift from the source files does require some programing proficiency, but the “README.md” file (which is always a good place to start navigating any set of source code files) provides the instructions should the prosodists be interested. MacArthur notes that Drift should be soon available for downloading.[58]
In the following video, I use the online demo version to show the kind of interface Drift offers. The audio file is Frost’s performance of “Mending Wall” recorded on May 5, 1933 as part of the literary and ethnographical studies at Columbia University called The Speech Lab Recordings project.[59] For the purpose of this Colloquy essay, I generated the transcription of the recording available at PennSound, first using Gentle, and uploaded a small fraction of this transcription to Drift in order to navigate the visualized pitch.
Evidently, Gentle’s transcription is far from accurate. While humans always need to intervene to double-check the accuracy of automatically generated transcription, I resolved to keep the rough transcription for the following reasons. First, when working with a large collection of audio recordings—as anyone working in the field of library science, I trust, can attest—any groundwork would make the labor-intensive transcription process more affordable. Second, by avoiding the imposition of the published text on the performed work, I quickly find myself tapping into a potential bibliographic research area, needing to determine whether to treat the performance as a unique work or to treat it as a variant of the printed work. Moreover, the production of transcriptions concerns the legal definition of copyright and fair use—something I am probing into as I prepare for my qualifying exams this summer. Lastly, Gentle is in active development, and its developing team encourages public testing and feedback. Therefore, I see community value in sharing the challenge of automatically transcribing a digitized 1933 recording.
[Pitch Analysis of Frost’s 1933 “Mending Wall” Recording Using Gentle and Drift]
Machine-Aided Close Listening (2017-Present)
The most recent addition to my historical overview of digital prosody projects is Machine-Aided Close Listening (MACL). Developed by Chris Mustazza in collaboration with developer Reuben Wetherbee, MACL is a web-based pedagogical program designed to assist critical inquiries of the phonotextuality of performed poems. [60] Following the critical framework of what Charles Bernstein calls “close listening,” MACL accommodates analyses of the interplay between 1) a poem’s text on a printed page, 2) a performance of that poem, and 3) a visualization of the audio recording of that performance. [61]
MACL is composed of open-source programs such as Praat, WaveSurfer, and ELAN in order to enable analyses of the poet’s pitch contours and of the sound visualization of a performance, and to facilitate inquiries based on the temporal duration of each line of a poem. Just like Drift, MACL accommodates an examination of pitch contour by letting users download a pitch data file in a .txt file—something, when aggregated en masse, might be useful for a quantitative analysis such as Marit MacArthur et al.’s “Poet Voice” study. [62] Since 2016, MacArthur et al.’s research has examined the sociocultural constitutions of poetry performance through comparative analyses of the poets’ pitch, intonation, and pitch speed;[63] The MACL program is designed to probe into a similar research question i.e., whether the visualization of an audio recording of a poetry performance can either confirm an impressionistic close listening experience or expose new kinds of sound dynamics a listening alone might miss. [64] MACL, particularly, is developed to serve such critical inquiries in a classroom setting and in other instances in which users benefit from examining the commonly viewable interface (in contrast to a few researchers having limited access to the visualization result). To support such dialectical objectives, MACL is available online, and is designed in a way for the users to listen to the audio file while concurrently following the pitch contour of a performance—a function that complements the preexisting program such as Drift.
Also unique to MACL is the temporal measurement of each line of a performed poem. Myopia and Poem Viewer, for example, attempt to visualize syllabic durations (either “long” or “short”) and vowel lengths (long, half-long, extra-short) in order to study the sonic pattern of poems based on the phonetics of English language. MACL, on the other hand, is interested in the interplay between typographical arrangements of a poem on a printed page and its aural rendition, and thus measures a performance by the unit of the line, amalgamating what are, quintessentially, performed text and printed text. Using such functions of MACL, for instance, Mustazza observes how Robert Frost’s 1933 reading of “Mending Wall” best captures the poet’s privileging a sentence unit over a line break. [65] Analogically, MACL may assist studies of such effects as enjambment, caesura, and breathing patterns. A study of such interplays between the phonotext and printed text—a perspective no other programs have offered to date—may be of interest to prosodists especially, since MACL can measure both formal and free verse and complicate the critical discourse around the constitutions of each form.
Currently, the program is embedded as a part of PennSound, and users can only study the examples prepared by Mustazza and his research assistant, Zoe Stoller. However, MACL’s gesture towards a juxtaposition of the written text and the aurality of a performed poem sheds light on a new model for critically discussing audio recordings of poems.
Conclusion
I hope this brief overview suggests how digital technologies have informed prosodic inquiry from the early 1980s to the present. Some projects have incorporated digital technologies as a means of exploratory prosodic research (Scansion Machine, the Scandroid) and pedagogies (for better for verse and Myopia), while others have produced digital technologies for prosodic analyses (Poem Viewer, Poemage, Drift, and Machine-Aided Close Listening). Some have even sought profits with then state-of-the-art software to assist the composition of metrical verse (Poetry Processor). Additionally, some projects have mostly concerned metrical verse (the Scandroid and for better for verse), while others have even ventured into the sonic structure of free verse (Poem Viewer and Poemage). To the best of my knowledge, I have not yet come across projects that specifically concern accentual meters or syllabic meters, and would like to know if there are any such efforts.
By way of a conclusion, I would like now to further consider some implications of using software for conducting prosodic analysis (such as Praat, ARLO, and Drift) and note the need for methodological analysis. As Tanya Clement articulates in “Where Is Methodology in Digital Humanities?,” literary research ought to retain its “sound” tradition of self-reflectiveness, especially when employing methodologies from the social sciences and linguistics.[66] Self-reflectiveness in this context entails careful examination of how software may condition the epistemology of prosody.
In particular, the histories and material conditions of digital technologies may be worth considering for exploring prosody. For instance, Mara Mills in “Deaf Jam: From Inscription to Reproduction to Information” illustrates the history of speech science and how the sound spectrograph—something Praat offers—was employed to train deaf students to master “normal speech.”[67] I may not intend to normalize anyone’s poetry recitation—let alone naturalize a reading of the composer—but if I employ the sound spectrograph carelessly, its history may inadvertently suggest an authoritative stance. By the same token, digital technologies may also help address the notion surrounding “authoritative” voices and intonational contours that are culturally constructed. Marit J. MacArthur and Lee M. Miller in their “Vocal Deformance and Performative Speech, or In Different Voices!,” for instance, examine the constitution of audial canonical texts by deforming the intonation and other vocal qualities, indicating how our perception of sound is historically conditioned.
Another easy slippage digital technologies present is the notion of immateriality. For instance, Jonathan Sterne in his MP3: The Meaning of a Format discusses historical techno-cultural investments in the physiology of sound, as well as the mechanics of recording devices and digital file formats.[68] Taking into consideration how the sound of poetry is mediated may be of interest to prosodists, so as to mitigate our blind trust in technologies. For example, Chris Mustazza in his “The Noise Is the Content: Toward Computationally Determining the Provenance of Poetry Recordings” probes into the mediation of sound itself, treating what a machine recognizes as “noise” as a historical signifier with which we might detect how the sound was recorded at a given time and place.
I think digital technologies for exploring prosody can be constructive, especially when the research looks for the moment in need of negotiation—that is, the time when we need to negotiate our knowledge of prosody and of digital technologies—just as the tension between the meter and rhythm of a line can be suggestive of human art.
Acknowledgements:
In preparing this essay, Natalie Gerber and Eric Weiskott kindly offered extensive comments and suggestions. They also helped me seek expertise from prosodists such as Thomas Cable and Charles Hartman. Thank you! I am also grateful for Tanya Clement, Laura Mandell, and Marit MacArthur for generously responding to my email inquiries. Lastly, I am indebted to Chris Nam, Alex Breiding, and Michael Hooker at the Division of Information Technology, the University of Maryland for their technical and moral supports, as I brought in open-source software programs, week after week, hoping to run them on my computer. Without their help, I could not have figured out all the command lines to configure some archaic, if not esoteric, programs. Needless to say, I am responsible for all the shortcomings in this essay, and I look forward to receiving feedback on how I can improve this working survey of digital prosody projects and prosody-related visualization methodologies. Additionally, I would like to know what other applications prosodists have made with the programs introduced in this essay and if there are additional programs they would add to the list.
[1] For this Colloquy essay, I limit myself to introducing programs developed and/or employed for exploring prosody of metrical verse in English. For more inclusive interpretations and expansive lists of early digital poetry composition, see C. T. Funkhouser’s Prehistoric Digital Poetry: An Archaeology of Forms, 1959-1995 (Tuscaloosa: University of Alabama Press, 2007); Nick Montfort’s “Memory Slam” as well as Loss Pequeño Glazier’s Digital Poetics: The Making of E-Poetries (Tuscaloosa: University of Alabama Press, 2002), and Media Poetry: An International Anthology edited by Eduardo Kac (Wilmington, NC: Intellect, 2007).
[2] Charles O. Hartman. Virtual Muse: Experiments in Computer Poetry. Lebanon, NH: University Press of New England, 1996, pp. 38-40.
[3] Allegedly, and according to the separate chronologies complied by Funkhouser and Kac, a Clair Philippy published five poems in the 1963 Electronic Age journal, using a medium-scale, built-for-business RCA 301 Electronic Data Processing System Mainframe Computer to create “blank verse at the rate of 150 words a minute” (Funkhouser, p. xx; Kac, p. 274). Unfortunately, and just as with so many other ephemeral digital projects, there is little record of how Philippy programmed composition. Scholars such as Bryan Bergeron in his Dark Ages II: When the Digital Data Die (Upper Saddle River: Prentice Hall PTR, 2002) and Trevor Owens in The Theory & Craft of Digital Preservation: An Introduction (Baltimore: Johns Hopkins University Press, forthcoming) address the ways to manage the fast obsolescence of digital artifacts. In the field of contemporary digital archival studies, consensus suggests the importance of documentation, if not the preservation of executable program itself (Dappert and Farquhar 2009; Webb et al. 2013; Engle 2015). My needing to start a historical overview of digital programs concerning English metrical verse with Hartman’s 1981 Scansion Machine rather than the 1963 enterprise of Philippy is yet another testimony to the need for digital preservation.
[4] Funkhouser, p. xxii. When the original publication date of the software and platforms are not explicit, I relied on my cross-examination of the following factors: 1) the earliest publication date of directly related concepts; 2) the copyright information in the source code or in the documentations otherwise available in the application package; and 3) notes and remarks published by the principal investigators and developers.
[5] Hartman, pp. 42-43.
[6] Hartman, pp. 43-46.
[7] Hartman, p. 53.
[8] According to The New York Times’s Peter H. Lewis, Michael Newman was a contributing editor of The Paris Review and also a protégé of W. H. Auden. In the article he published in the computer magazine Byte, Newman introduces Hillel Chiel as a researcher at Columbia Medical School and Paul Holzer as a programmer and analyst for the stock brokerage company Paine Webber. Judging from Hartman’s remarks on the progressive artificial intelligence research taking place in the field of medicine (Hartman, p. 49), that Newman collaborated with Chiel appears reasonable, even though I rarely see a collaboration between health information scientists and poets today.
[9] Trevor Owens in his Designing Online Communities (Peter Lang, 2015) entertains the idea of “users” as “generalized others,” a cultural construct defined by the developers and administrators of online communities. For the purpose of this Colloquy essay, I resolved to use the term user, hoping to showcase how each program imagines its intended users differently.
[10] Holzer in his “Machine Reading of Metric Verse” column in Newman’s Byte magazine article “Poetry Processing,” p. 224.
[11] Robert Frost, “Poetry and School,” Atlantic Monthly, June 1951. Collected Poems, Prose, and Plays, edited by Richard Poirier and Mark Richardson, The Library of America, 1995, p. 809.
[12] The second article came a year later, and Lewis reports again on the Poetry Processor as a part of his contemporary educational software reviews.
[13] The English Journal, Vol. 77, No. 6 (Oct. 1988).
[14] The Electronic Rhyming Dictionary was priced at $59.95 (equivalent to $132.83 in 2017) and the Orpheus A-B-C, at $49.95 (equivalent to today’s buying power of $110.67).
[15] Paul Boersma is Professor of Phonetic Sciences at the University of Amsterdam and David Weenink is a researcher at the Institute of Phonetic Sciences in Amsterdam, The Netherlands.
[16] At a 2012 Big Data & Uncertainty Conference held at the University of Kansas, Katharine Coles and Julie Lein—both poets and scholars at the University of Utah—described how they, as they launched the Poem Viewer project, paid close attention to the sonic patterns of poetry including the “modulation between short and long vowels.”
[17] Robert Frost: Poems, Life, Legacy. Created by Joe Matazzoni, edited by Donald Sheehy, and narrated by Richard Wilbur, Henry Holt and Company, 1997. I reconstructed the CD-ROM (originally developed for Windows 95 and Mac OS 7.1) by setting up a virtual Windows 95 on my laptop using VMware.
[18] My preliminary research suggests that what is available on the online HarperAudio platform corresponds to the sequence of works and the note on recording date/place found on the cover slip of the Caedmon record, Robert Frost Reads His Poetry (TC1060). Evidently, HarperAudio is an official distributor of HarperCollins Publishers, which oversees the Caedmon Audio record label imprints.
[19] This line of inquiry is often recognized as media archeology. For instance, Chris Mustazza, as discussed in the “Conclusion” section of this essay, has used ARLO to investigate the noise of audio recordings in order to determine how the sound has been mediated. (See also: “ARLO” section of this essay.)
[20] For a definition and exemplary critical code studies project, see: Marino, Mark C. “Reading exquisite_code: Critical Code Studies of Literature.” Comparative Textual Media: Transforming the Humanities in the Postprint Era, edited by N. Katherine Hayles and Jessica Pressman, University of Minnesota Press, 2013, pp. 283-309. Mark C. Marino, a director of The Humanities and Critical Code Studies Lab at the University of Southern California, writes that the inclusion of the code in the published materials itself suggests that the codes are part of the work of scholarship and are “to be read, examined, and interpreted” (Marino, p. 290) Critical code studies, in my opinion, is a happy marriage between textual scholarship and information science. Or, as Matthew Kirschenbaum puts it, “where computer science and cultural studies collide.”
[21] Hartman, “the Scandroid Manual,” pp. 14-15.
[22] This command line calls for a human intervention in determining what a “plausible” foot may be. Hartman also notes this algorithm’s shortcoming by testing it (the foot type “3.b” in my description above) with Larkin’s “Church Going” and concludes the algorithm’s success rate is approximately 90%. The early steps in the algorithm (the foot type “3.a.ii” above), however, ensure the success rate of “near 100%, depending on lexical details” (Hartman, the Scandroid Manual, p.15).
[23] I used the text of “Mending Wall” from the 1995 Library of America edition. Frost, Robert. “Mending Wall,” Collected Poems, Prose, and Plays, edited by Richard Poirier and Mark Richardson, The Library of America, 1995, pp. 39-40.
[24] A high-level programing language, in short, is a translation of a machine language. It is often a combination of natural language and other functional terms. A programming language like Python offers a “humane” framework in assisting programmers, lest they need to constantly work with the codes that are more machine-friendly (a sequence of numerals and/or technical combinations of letters).
[25] Herbert F. Tucker. “Poetic Data and the News from Poems: A For Better for Verse Memoir.” Victorian Poetry, Vol. 49, No. 2, “Victorian Prosody” (Summer 2011), pp. 267-281.
[26] One of the infrastructural challenges prosodists and other literary students and scholars face is the copyright regulations. These regulations inevitably inform the availability of digitized and born-digital audio resources and the feasibility of scholarship (Do scholars need to pay for and/or request permissions from the copyright holders in order to study the materials?). Tucker in his “Memoir” notes that despite his wish to “let open access reign in the commons of pedagogy,” his University Counsel advised otherwise concerning the legal limitation of fair-use concerning the online publication: “Thou Shalt Not Infringe Copyright was a commandment that cost the [4B4V] some fine teaching examples from Frost and Auden, Yeats and Parker.” See Tucker, p. 270.
[27] Ibid., p. 274.
[28] Ibid., p. 4.
[29] Marit MacArthur, for instance, speculates how a study of intonation patterns may be fitting to the poetics of Robert Frost.
[30] Helen Armstrong is Creative Director of the Augmented Reality Center and Graduate Director of Experience Design; Laura Mandell is Director of the Initiative for Digital Humanities, Media, and Culture at Texas A&M University; Gerald Gannod is Professor of Computer Science and Engineering, Miami University; Eric Hodgson is Small Center Director AIMS, Miami University; and Manish Chaturvedi is now a Miami University graduate. As a part of his master’s thesis project, Chaturvedi participated and played an essential role in the Myopia research group under the supervision of Gannod and Mandell. Learn more about the project’s team at the portfolio page of The Augmented Reality Center, Miami University.
[31] See the video recording of Mandell’s talk “Myopia: A Visualization Tool in Support of Close Reading.”
[32] Manish Chaturvedi. “TEI Poetry Visualization Tool: A Users [sic] Guide” in “Visualization of TEI Encoded Texts in Support of Close Reading,” A thesis submitted to the Faculty of Miami University in partial fulfillment of the requirements for the degree of Master of Computer Science Department of Computer Science and Software Engineering, Miami University, 2011, p. 5.
[33] Chaturvedi, “Visualization of TEI Encoded Texts in Support of Close Reading,” pp. 1-5.
[34] Ibid., pp. 22-33. Also see Chaturvedi, “TEI Poetry Visualization Tool: A Users [sic] Guide,” p. 9.
[35] Mandell et al., “Myopia: A Visualization Tool in Support of Close Reading,” DH 2012 Hamburg, 18 July 2012. Objectives for scansion activities in the classroom can be multifold. When incorporated with archival scholarship, students’ scansion can contribute to the most time-consuming and expensive metadata production of a digital archive such as The Poetess Archive. Any form of metadata would be helpful in terms of enhancing the resource’s retrievability on the Internet. In due course, the varieties among the XML encodings can be discussed among the students and instructors not only in terms of literary interpretations but also in terms of inventing the ways to make the digital technologies embrace the complexity of human culture. Markup schema of Emily Dickinson's Correspondences reflect this rationale, and The Shelley-Godwin Archive incorporates markups produced by undergraduate and graduate students as part of their course assignments (see “Encoding Contributors” under the “About” page).
[36] Notably, and as I mention in passing in the video clip for 4B4V, Tucker shares his rationale for not incorporating audio recitations into the 4B4V project, lest oral interpretation of poems distract students who are mastering elementary scansion. See Tucker, p. 269.
[37] Katharine Coles is Professor of English at the University of Utah and Min Chen is Professor of Scientific Visualisation, Pembroke College, University of Oxford (Poem Viewer, “About”). Other collaborators include Alfie Abdul-Rahman, Chris Johnson, Julie Lein, Eamonn Maguire, Miriah Meyer, and Martin Wynne. At a 2012 Big Data & Uncertainty Conference at the University of Kansas, Katharine Coles noted how this international collaboration was realized owing to various circumstances, including colleagues of her spouse and a computer scientist Chris Johnson approaching her with a proposal to pursue an info-graphics research project with poetry. The project was funded as a part of the international Digging Into Data Challenge program.
[38] Alfie Abdul-Rahman, Julie Lein, Katharine Coles, Eamonn Maguire, Miriah Meyer, Martin Wynne, Chris Johnson, Anne Trefethen, and Min Chen. “Rule-based Visual Mappings with a Case Study on Poetry Visualization.” Eurographics Conference on Visualization (EuroVis) 2013, Vol. 32, No. 3.
[39] Ibid.
[40] As a screenshot of the Internet Archive’s Wayback Machine suggests, Poem Viewer used to let users upload a poem and so automatically translate the poem into its phonetic transcription. Users were asked to choose a preferred language between US English and British & World English, presumably owing to the program’s dependence on the Oxford Dictionaries API (Application Program Interface). Recent interface suggests that Poem Viewer no longer works in concert with the Oxford Dictionaries. As the program goes through continuous development—just like any other online digital project—it is difficult to determine what may be the reasons behind the recent change. The text of “The Wood-Pile” is from the 1995 Library of America edition. Frost, Robert. “The Wood-Pile,” Collected Poems, Prose, and Plays, edited by Richard Poirier and Mark Richardson, The Library of America, 1995, pp. 100-101.
[41] Email correspondence with Tanya Clement, 14 February 2017.
[42] Tanya Clement, David Tcheng, Loretta Auvil, Tony Borries. “Introducing High Performance Sound Technologies for Access and Scholarship.” The International Association of Sound and Audiovisual Archives Journal Vol. 41, September 2013, pp. 23-24.
[43] For instance, Edward Garnett praised Frost’s North of Boston as “[s]urely a genuine New England voice” in a 1915 Atlantic Monthly. In her famous 1915 New Republic review, Amy Lowell also wrote: “Living in England [Mr. Frost] is, nevertheless, saturated with New England. For not only is his work New England in subject, it is so in technique. No hint of European forms has crept into it. It is certainly the most American volume of poetry which has appeared for some time. I use the word American in the way it is constantly employed by contemporary reviewers, to mean work of a color so local as to be almost photographic.” For more of Lowell’s review see Lowell, Amy. “North of Boston.” The New Republic, Vol. 2, 20 February 1915, pp. 81-82.
[44] Chris Mustazza offers a wonderful observation on the exceptional performance of Frost within the context of The Speech Lab Recordings, literary and ethnographical studies at Columbia University that were led by the lexicologists and scholars of American dialects George W. Hibbitt and W. Cabell Greet between 1931 and 1942.
[46] Sylvester Baxter. “New England’s New Poet.” The American Review of Reviews, Vol. 51, edited by Albert Shaw, April 1915, pp. 432-434.
[47] See “Background and Related Work” in Clement et al., pp. 21-28.
[48] McCurdy et al. define four rhyming types as follows: “sonic rhyme involves the pronunciations of words; phonetic rhyme associates the articulatory properties of speech sound production, such as the location of the tongue in relation to the lips; visual rhyme relates words that look similar, such as cough and bough, whether or not they sound alike; and structural rhyme links words through their sequence of consonants and vowels.” For more details, see McCurdy, Nina, Vivek Srikumar, and Miriah Meyer. “RhymeDesign: A Tool for Analyzing Sonic Devices in Poetry.” Proceedings of NAACL-HLT Fourth Workshop on Computational Linguistics for Literature, 4 June 2015, Association for Computational Linguistics, 2015, pp. 12-4.
[49] Ibid., pp. 14.
[50] I counted how many rhyme patterns RhymeDesign and Poemage offer based on their interface designs.
[51] Nina McCurdy, Julie Lein, Katharine Coles, and Miriah Meyer. “Poemage: Visualizing the Sonic Topology of a Poem.” IEEE Transactions on Visualization and Computer Graphics, Vol. 22, No. 1., 2016. IEEE, 2015, p. 444.
[52] The text of “The Wood-Pile” is from the 1995 The Library of America edition. Frost, Robert. “The Wood-Pile,” Collected Poems, Prose, and Plays, edited by Richard Poirier and Mark Richardson, The Library of America, 1995, pp. 100-101.
[53] With MacArthur’s ACLS Digital Innovation Fellowship fund, Drift was developed by Robert Ochshorn and Max Hawkins in 2016, according to MacArthur.
[54] Marit MacArthur. “Introducing Simple Open-Source Tools for Performative Speech Analysis: Gentle and Drift.” 6 June 2016. Jacket 2, Kelly Writers House, 2017.
[55] Email correspondence with Marit MacArthur on 2 April 2017.
[56] Additionally, and just as many other collaborative, multifaceted digital projects, both Drift and Gentle are parts of other computer science research projects. For instance, Drift uses an algorithm designed by Dan Ellis (who is currently a research scientist at Google, Inc.) and Gentle uses a speech recognition program called Kaldi, an open-source program developed from a workshop held at Johns Hopkins University in 2009.
[57] GitHub is an online repository mainly used for sharing codes and facilitating programing collaborations. As its personal account keeps the record of how much contributions one has made and to what projects, GitHub also functions as a portfolio of programmers, especially if they are invested in the open-source movement.
[58] Email correspondence with Marit MacArthur on 2 April 2017.
[59] This recording is available owing to the superb scholarship of Christ Mustazza at the PennSound. For more contextual information, see the “Robert Frost” page on the PennSound curated by Mustazza.
[60] Chris Mustazza is the Associate Director of the PennSound, IT Director for Penn’s School of Arts and Sciences, and a PhD candidate in the English Department at the University of Pennsylvania.
[61] Chris Mustazza. “Machine-aided close listening: Prosthetic synaesthesia and the 3D phonotext.” Digital Humanities Quarterly, forthcoming.
[62] Marit MacArthur, Georgia Zellow, and Lee M. Miller. “Beyond Poet Voice: Sampling the (Non-) Performance Styles of 100 American Poets.” Journal of Cultural Analytics, 18 April 2018, doi: 10.22148/16.022.
[63] Ibid.
[64] For more detail, take a look at Mustazza’s talk delivered at the Maryland Institute for Technology in the Humanities on April 3rd, 2018 titled “Dialectical Materialities: PennSound, Early Poetry Recordings, and Disc-to-Disk Translations.”
[65] Ibid.
[66] Tanya E. Clement. “Where Is Methodology in Digital Humanities?” Debates in the Digital Humanities 2016, edited by Matthew K. Gold and Lauren F. Klein, University of Minnesota Press, 2016, pp. 153-175.
[67] Mara Mills. “Deaf Jam: From Inscription to Reproduction to Information.” Social Text 102, Vol. 28, No.1, Spring 2010, Duke University Press, 2011, p. 38.
[68] Jonathan Sterne. MP3: The Meaning of A Format. Durham: Duke University Press, 2012.
